When is the most amusing part?
The funny moment is from frame 70 to 140.
What happened during the entertaining segment of this video?
A man tried to get some ketchup and couldn't pour it out, so he vigorously shook the ketchup bottle, but unintentionally splattering the person eating a burger with ketchup.
Why the segment is funny?
This video is funny for two main reasons. Firstly, the comedic element arises from the accidental ketchup spill that lands on the man's face. Moreover, the man's expression of shock, coupled with his ketchup-covered visage, elicits contagious laughter.
Please give this humorous short video a vivid and appropriate title.
Miracle Tomato Sauce.
What's the most interesting moment of this video?
The most intersting moment is from frame 22 to 211.
Can you describe the humorous segment of this video?
There was a small toy at the door of the bathroom. A black and white cat went behind the bathroom door and started to use its paws to reach its toy from the doorway.
Why is this video interesting and engaging?
The cat could have taken its toy directly to play, but it had to go behind the door to reach its toy from the doorway. As the paws are too short to reach to reach, this behavior result in a cute and funny scene.
Write an suitable title for this funny video.
Legs are never longer than enough.
When is the creative segment of the video?
The creative moment is from frame 2 to 53.
What happened during the creative segment?
In the middle of the stage was a man sitting on a chair playing the guitar. A little girl wearing piano outfit turned around. Then she took off the outermost clothes and made herself inverted. The man picked her up
onto his shoulders, and his one hand held the girl's legs, the other hand catched a small wooden stick.
Why do you think the segment is creative?
The creative point of this video is that, the little girl changes outfits and body postures constantly to simulate the violin, with the man simulating the scene of playing the violin.
Please give this creative video a title to best represent its shine point. Also, score the creativity of the video on a scale of 0 to 20.
The title is: the 'startled' concert. And I will score this video 19 for creativity.
In what period the magic took place?
The magic moment is from frame 71 to 119.
Can you describe the magical segment of this video?
The man reached out his hand, took one of the clouds from the sky, and put it into his mouth.
How can you tell that the video showcases magic?
What's commonsense-violating is that, people standing on the ground can't touch the clouds, so the clouds can't be taken down by the man.
What method do you think the magician used to accomplish the magic trick?
The magician used video editing technology to combine a video of reaching for the cloud with a video of eating a marshmallow to create the magic effect.
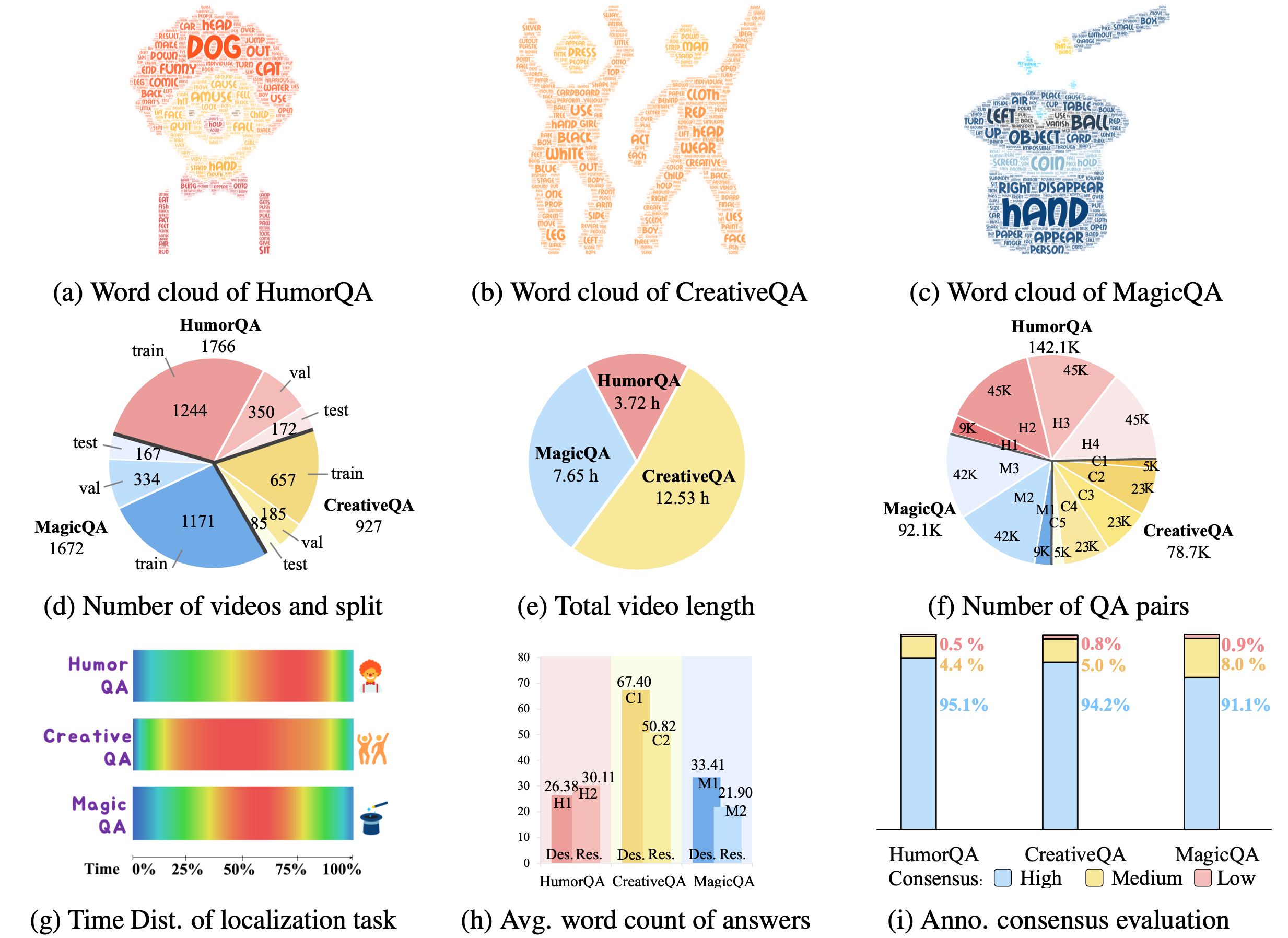
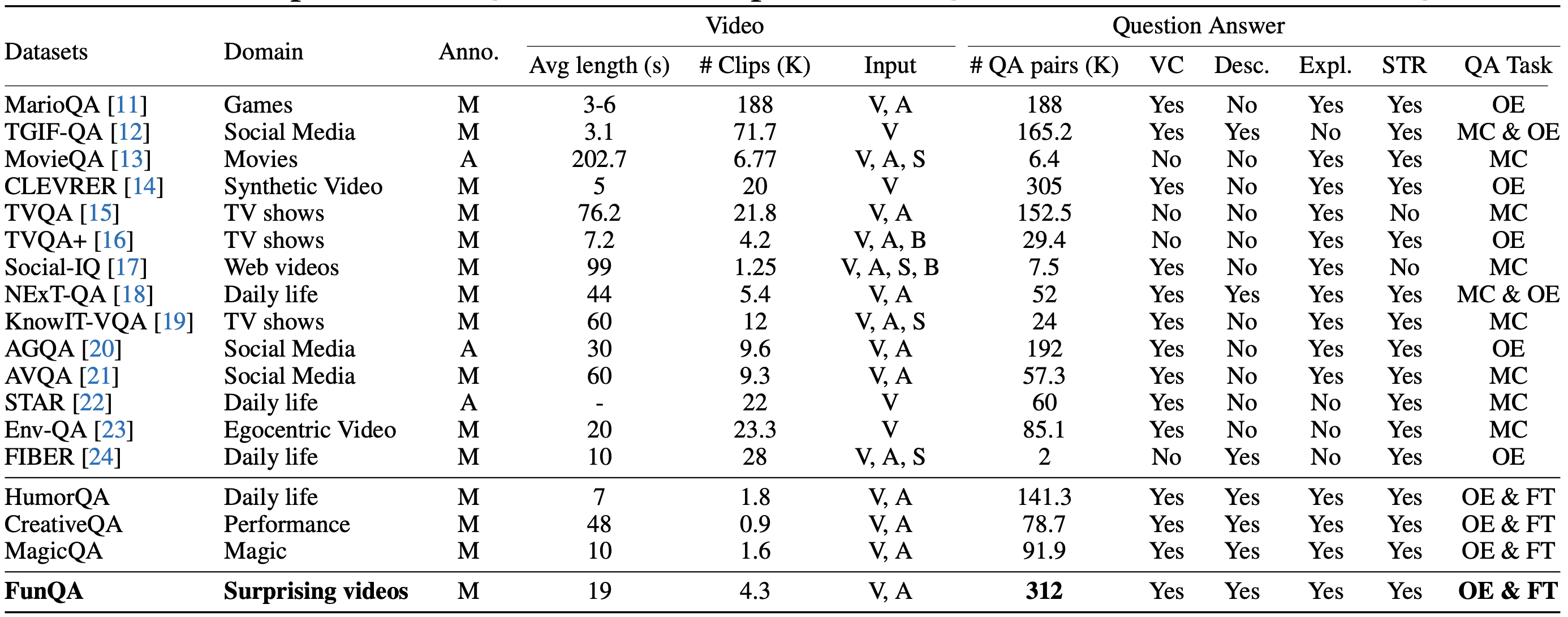
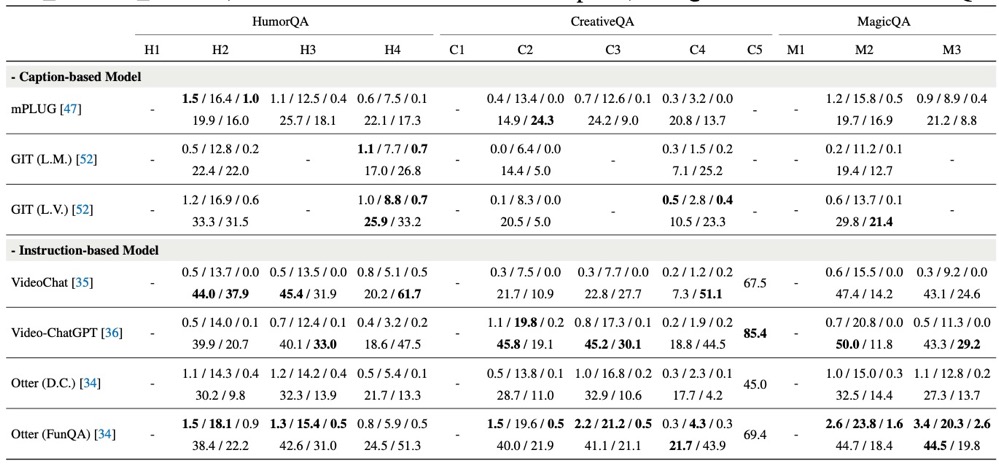
Surprising videos, e.g., funny clips, creative performances, or visual illusions, attract significant attention. Enjoyment of these videos is not simply a response to visual stimuli; rather, it hinges on the human capacity to understand (and appreciate) commonsense violations depicted in these videos. We introduce FunQA, a challenging video question answering (QA) dataset specifically designed to evaluate and enhance the depth of video reasoning based on counter-intuitive and fun videos. Unlike most video QA benchmarks which focus on less surprising contexts, e.g., cooking or instructional videos, FunQA covers three previously unexplored types of surprising videos: 1) HumorQA , 2) CreativeQA, and 3) MagicQA. For each subset, we establish rigorous QA tasks designed to assess the model’s capability in counter-intuitive timestamp localization, detailed video description, and reasoning around counterintuitiveness. We also pose higher-level tasks, such as attributing a fitting and vivid title to the video, and scoring the video creativity. In total, the FunQA benchmark consists of 312K free-text QA pairs derived from 4.3K video clips, spanning a total of 24 video hours. Moreover, we propose FunMentor, an agent designed for Vision-Language Models (VLMs) that uses multi-turn dialogues to enhance models’ understanding of counterintuitiveness. Extensive experiments with existing VLMs demonstrate the effectiveness of FunMentor and reveal significant performance gaps for the FunQA videos across spatial-temporal reasoning, visual-centered reasoning, and free-text generation.

@inproceedings{xie2025funqa,
title={Funqa: Towards surprising video comprehension},
author={Xie, Binzhu and Zhang, Sicheng and Zhou, Zitang and Li, Bo and Zhang, Yuanhan and Hessel, Jack and Yang, Jingkang and Liu, Ziwei},
booktitle={European Conference on Computer Vision},
pages={39--57},
year={2025},
organization={Springer}
}